

Today we’re talking to Devansh Varshney, who added histogram chart support to LibreOffice and is working on improvements to the Basic IDE…
Tell us a bit about yourself!
I am from Mathura in India, one of the historical cities where the first image of Buddha was carved during the Kushan Empire, Jain Tirthankar Neminatha’s birthplace and the more famous Bhagwan Krishna birthplace. A city where Greek kings also ruled and whose history has been documented by many travellers, the more famous Xuanzang and Faxian.
The rich history and diverse art culture of Mathura also reflects my interests too. My interests range from history to astrophysics to economics, and from tweaking custom Android ROMs back in high school to now tweaking the LibreOffice codebase which is one of the most interesting puzzles I came across. Even the people around me noticed and back in school I was given the name “Internet” – which was quite an interesting name but really reflects my nature.
Besides working on the LibreOffice codebase, I am also planning to complete my book on ADHD which I have mapped around first principles and physics. Hopefully by next year it will be complete.

Vishram Ghatl on the banks of river Yamuna in Mathura (image: Umang108 on Wikimedia, CC-BY-SA)
{kind=link}
What are you working on in the LibreOffice project right now?
This year I am working on making the Basic IDE better and more powerful by introducing a new Object Browser in the IDE, which is one of the most-demanded features as users working with LibreOffice had to visit the online API webpage to refer to the details of UNO APIs. That was quite a friction, and slows down not just the work but also decreases the user experience specially for macro developers.
Along with this, there is also the Basic code suggestion which will be available to users, so that they do not have to look every time what is going to be put when the suggestion can show the list of possible parameters and variables that can be placed.
Why did you choose to join the LibreOffice project, and how was the experience?
This is an interesting question. Back in 2017-2018 I experienced a lot of challenges with the Chrome browser, and thought about fixing them. That’s when I came across the Chromium project – upon which Chrome is based – and I did try to ask how to contribute and got some reply, but it was different from what I got in the LibreOffice project.
Here I did not get silence or confusion when I picked a bug, rather people showed interest and curiosity, and helped me do what I intended to fix. I am not putting other open-source projects on a pedestal – it’s just what I experienced at LibreOffice.
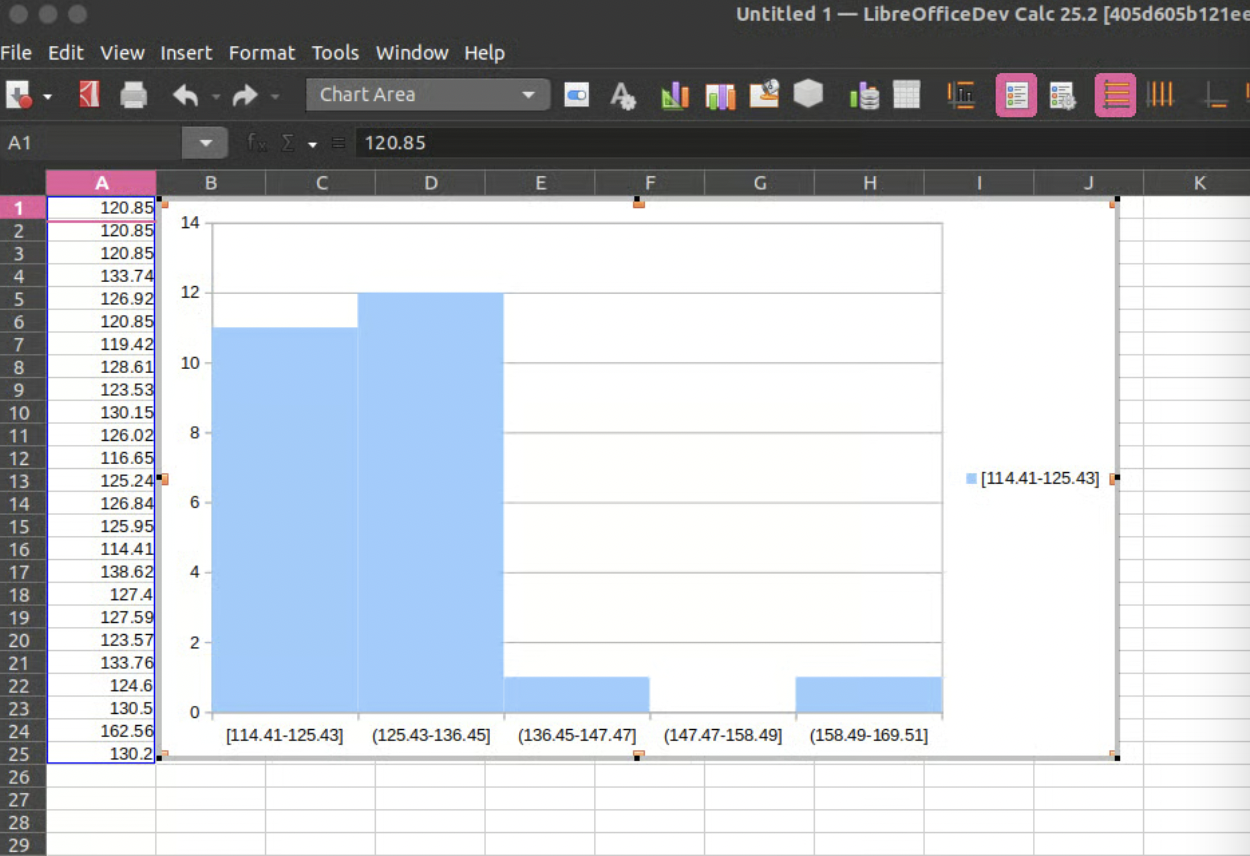
I also made some small contributions to the Google Benchmark and Blockly project and Phoenix Framework previously, but the big twist came last year when Ilmari got curious and asked me why I hadn’t mentioned the Google Summer of Code (GSoC) yet and pushed me to apply for 2024. I looked at the projects and found “Adding Native Histogram support to LibreOffice“.
Since in the past I had worked with machine learning, I saw that the need for these new chart types is crucial. But this is not just the point — while preparing the proposal for the histogram project, I found that CERN uses LibreOffice for their work and they even had a tutorial on a workaround of making histogram charts via column charts (link).
Which showed me two things: first, the lack of this feature is not just slowing human research, but also that the impact of LibreOffice is worldwide. This was the exact moment I realised that LibreOffice is not just about an office suite that lets people have autonomy over their data – but also its impact on human evolution and development is of sheer size.
Anything else you plan to do in the future? What does LibreOffice really need?
Yes, there is a lot of work remaining. First and foremost is the addition of Histogram Chart and other new chart types, as we later found challenges with how charts are being mapped in the codebase, and the newly introduced namespace by Microsoft for OOXML export made work more challenging. Then this year I got more interested in OCR with images and files like PDFs, natively available to users locally.
I tried to make an extension with Tesseract but its efficiency is not that great and it misses the whole structure of how the text was in the image.
Since LLMs (large language models) are something famous nowadays, I looked at how they are processing and reading images, and found they really can’t read images directly. The images first have to be processed by something called Vison Language Models (VLMs).
Nowadays there are some amazing open-source VLMs available which are also small in size and can run locally – even with the computing power of a mobile device. So I am also looking at ways we can get this working with LibreOffice, so that not just OCR but also reliable translation from text to the captured structure and modifying that structure can be done.
Many thanks to Devansh for the great contributions to LibreOffice! Everyone is welcome to find out what they can do to make the suite even better 😊